



北京基因组所(国家生物信息中心)多组学数据资源体系持续拓展和更新
在2024年1月正式出版的国际生物数据库期刊《核酸研究》(Nucleic Acids Research)2024年度数据库专刊上,中国科学院北京基因组研究所(国家生物信息中心)国家基因组科学数据中心(CNCB-NGDC)共有10篇论文集中亮相,包括1篇数据库整体介绍和9篇数据库论文,展示了中心多组学数据资源体系建设的最新成果。自2018年以来连续7年被该刊称为与美国国家生物技术信息中心(NCBI)、欧洲生物信息学研究所(EBI)并列的全球主要生物数据中心。
2023年,CNCB-NGDC与2家共建单位以及30多家合作单位密切协同,重点加强多组学数据整合与知识融合,不断升级核心数据库(GSA、GWH、GVM、GEN、GenBase、MethBank、LncRNA、RCoV19等),并开发了多个全新数据库,包括原生生物(P10K)、细菌(NTM-DB、MPA)、植物(PPGR、SoyOmics、PlantPan)和疾病/性状关联(CROST、HervD Atlas、HALL、MACdb、BioKA、RePoS、PGG.SV、NAFLDkb)等不同类型的数据资源,进一步拓展了涵盖基础组学、国家人类遗传、重要战略生物、病毒等资源信息库以及生物信息在线分析工具等在内的多组学数据资源体系,为国家基因组科学数据的汇交共享、安全管理和挖掘利用提供了重要支撑。
CNCB-NGDC汇聚全球数据,免费为国内外用户提供一站式多组学数据汇交和存储服务,发布的数据编号被Springer Nature、Elsevier、Wiley、Taylor & Francis、Cell等全球主要学术出版集团认可。2023年组学原始数据归档库GSA成功入选全球核心生物数据资源GCBR,是我国目前唯一入选的数据库。截至2023年12月底,组学原始数据管理体系(GSA Family)已支持各类科技项目17,000多个,汇交数据量超40PB,来自912家单位5,300多个用户,相关数据已在572种国内外期刊的3,000多篇文章发表。新冠病毒信息库(RCoV19)进一步升级,已收录新冠病毒序列超1,700万条,为全球182个国家/地区400多万名访客提供数据服务,累计数据下载达190多亿条,在新冠病毒演化分析、监测等方面发挥了重要作用。
CNCB-NGDC的建设得到科技部、财政部、中国科学院、国家自然科学基金委、一带一路国际科学组织联盟、国际生物科学联合会等的资助。
CNCB-NGDC在《核酸研究》2024年数据库专刊发表的论文(含共同合作论文):
5. 人类内源性逆转录病毒相关疾病知识库HervD Atlas
10. 热带作物组学数据库TCOD
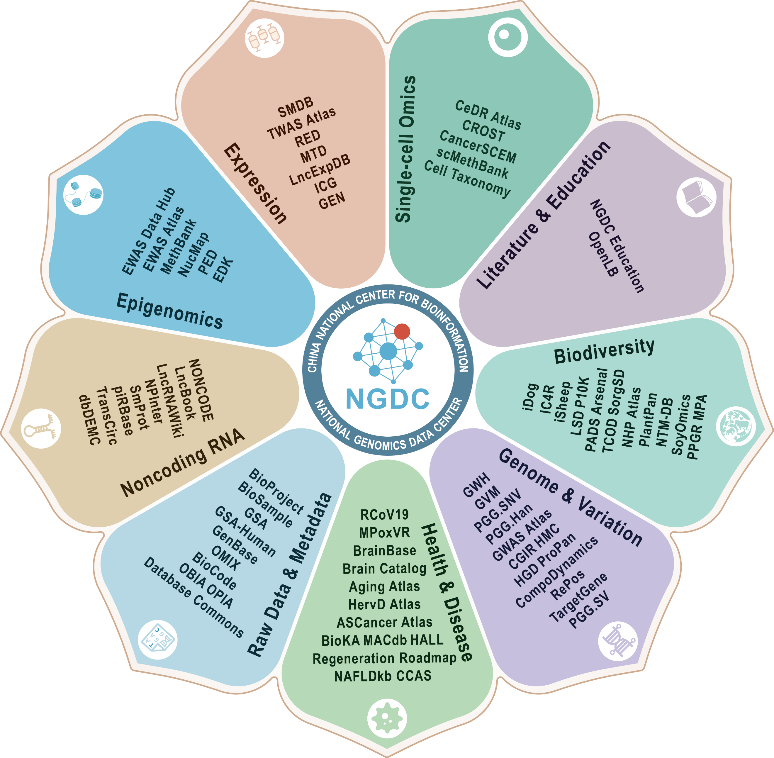
CNCB-NGDC多组学数据资源体系(Nucleic Acids Res 2024)


