



国家生物信息中心发布蛋白翻译效率动力学解析综合数据库TEDD
蛋白翻译是中心法则的核心环节,更是基因表达调控与生物制造的关键步骤。高通量测序技术(RNA-seq、Ribo-seq、RNC-seq等)的飞速发展,为全基因组水平综合评测翻译效率(TE)、翻译起始效率(TR)、翻译延伸速率(EVI)三大核心动力学指标提供了技术支撑。但当前研究仍存在明显局限:缺乏基因与转录本双水平的系统量化整合,5'/3'非编码区(UTR)注释不完善,难以深入探究顺式调控元件的作用,这些都极大限制了其在 mRNA 疫苗设计、合成生物学、基因治疗、酶工程等生物制造领域的应用。
近日,国家生物信息中心开发并上线蛋白翻译效率动力学解析综合数据库TEDD(Translation Efficiency Dynamics Database),相关成果以“TEDD: a comprehensive database for translation efficiency dynamics”为题,在国际学术期刊“Nucleic Acids Research”在线发表。
TEDD作为聚焦人类转录组与翻译组数据的公共资源平台,当前版本整合了143个项目的279个数据集,涵盖1518个样本、24种组织/细胞类型、74种细胞系及52种培养条件。数据库提供了23976个基因和154622个转录本(可变剪切体)在不同生物学背景下的TE、TR、EVI三大指标,更创新性地首次整合UTRdb 2.0与IRESbase数据库资源,完成了所有转录本的UTR注释,包含内部核糖体进入位点(IRES)、上游开放阅读框(uORF)、miRNA结合位点、多聚腺苷酸(polyA)信号、重复序列、Rfam基序等关键调控元件信息,为解析翻译调控机制解析和生物制造提供了细颗粒度的数据支撑。
TEDD集成浏览、搜索、分析、下载四大核心模块,支持从数据集、样本、基因三个维度快速获取所需信息。其特色数据分析与可视化功能包含三大核心模块,满足多场景研究需求:
基因水平翻译效率分析:可探索同一基因下所有转录本的翻译效率及UTR特征。既能识别跨生物背景稳定高表达的转录本(如COX7C、TPT1等基因偏好的高TE转录本,其UTR区域含miRNA结合位点、polyA信号等优势特征,为mRNA疫苗设计与合成生物学改造提供参考),也能发现疾病特异性转录本偏好(如免疫治疗靶点PRAME在不同肿瘤类型中呈现独特5' UTR特征,为靶向治疗策略开发提供依据)。
转录本水平动态分析:聚焦特定转录本在不同生物学背景下的TE/TR/EVI变化,揭示环境依赖性调控机制。例如EGFR基因转录本ENST00000455089在多种癌症中表现出显著TE差异,反映异构体转换现象,为疾病特异性靶点筛选提供线索。
功能基因集富集分析:支持解析KEGG 通路或GO条目相关基因的翻译效率特征。以肾横纹肌样癌细胞的PI3K-Akt信号通路为例,上游调控因子(PDPK1、HSP90家族等)TE升高可促进AKT1/AKT2激活,进而增强下游MDM2对TP53的抑制作用,为阐明癌症发生机制提供了翻译调控层面的新视角。
作为当前整合规模最大的人类翻译组学数据库,TEDD实现了基因与转录本双水平指标量化、UTR调控元件深度注释、多维度数据比较分析的三大突破,显著超越现有同类资源。该数据库不仅为翻译效率动力学研究提供了全面系统的资源支撑,更在mRNA疫苗开发、合成生物学、基因治疗、酶工程等生物制造领域具有重要应用价值,将助力科研人员实现基因表达系统的精准设计与高效蛋白质生产。
本研究由国家生物信息中心陈非研究员、肖景发研究员担任共同通讯作者,赵文明研究员提供关键指导,研究得到国家重点研发计划、中国科学院先导等项目资助。
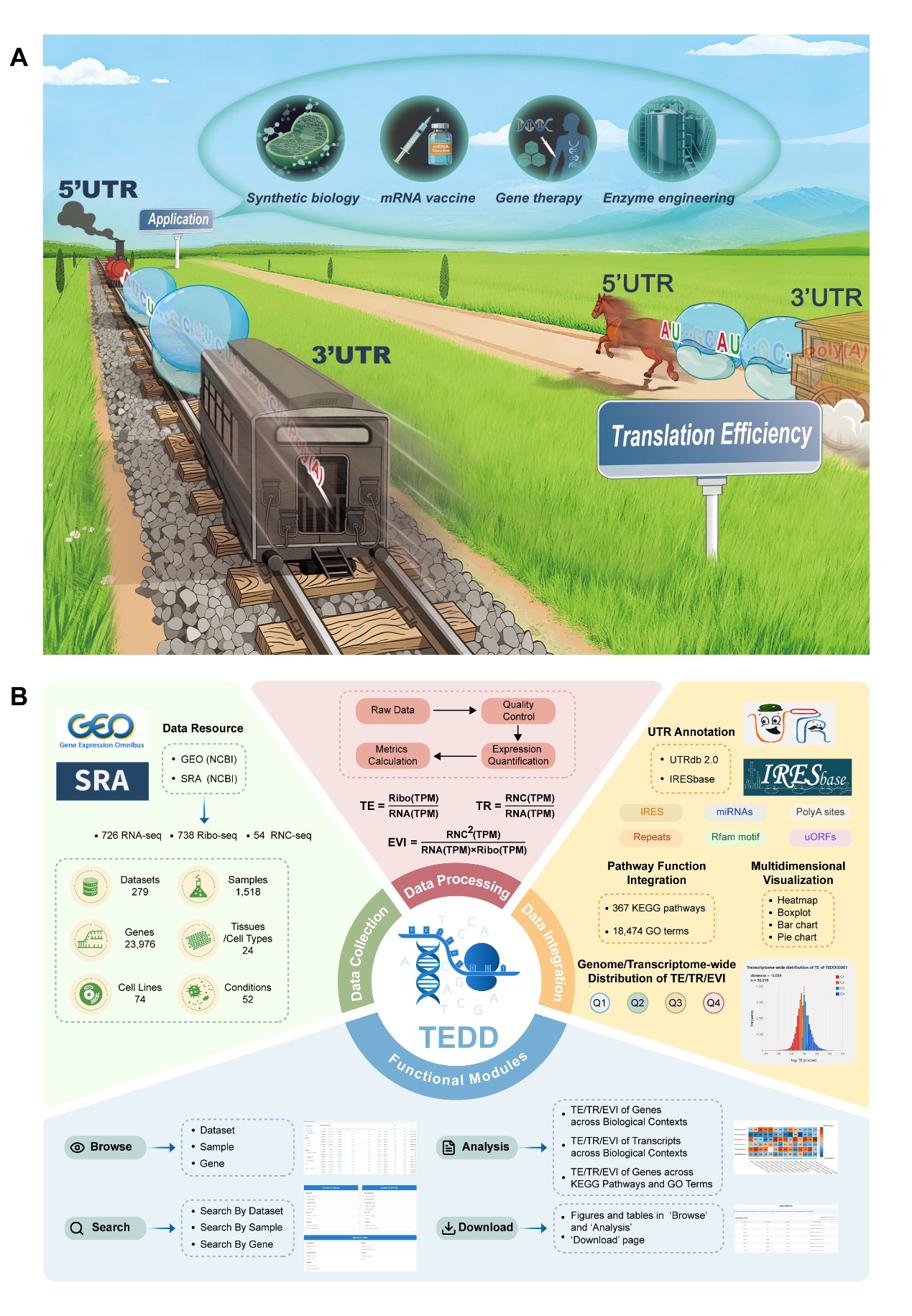
翻译效率及TEDD数据库四大功能模块概览


